Well-performing queries in OLAP scenarios with aggregate tables
Introduction
How many units of a particular product have been sold in Europe in Q1/2008? What was the sales volume of my subsidiary on the Island of Fiji in 2007? These are typical business critical questions, which management may demand from the back office. To answer these questions, the relevant data volume can be > 100 million records, especially for a big, world-wide operating company. Processing must be – of course – fast. For an IT department head or for a database administrator, this is quite a common requirement. You want to spend >20K Euro on licenses for “well-known” commercial database management systems (DBMS) to handle this requirement? No? Then read on.
The queries mentioned in the introduction are typical for OLAP (Online Analytical Processing) scenarios. From a technical implementation point-of-view, this is usually done with a Data Warehouse [1] (DWH). In such a system, aggregates play a very important role, because an OLAP query is usually an aggregated view on existing (relational) data. In SQL, you are probably familiar with aggregate functions like: COUNT, SUM, AVG, MIN and MAX.
This article shows how to speed up aggregated queries by using pre-aggregated data. It explains the concepts behind this, and describes a not that typical application domain for data warehousing. It is an entire solution based on Open Source technology, using the Firebird [2] DBMS and Mondrian [3], an Open Source OLAP Server. Mondrian does not have its own (multi-dimensional) storage engine, but follows the relational OLAP (ROLAP) paradigm, namely accessing data in an existing relational database.
Industrial DWH
The most common application domain for DWH is still: ”Everything related to sales statistics”. This is true, but not a necessity. Industrial manufacturing is an excellent example of a different application domain, where DWH concepts and implementations can also be applied. Large amounts of process and measurement data, which are generated during a production process, must be integrated in a DWH for further analysis tasks. Important goals for the usage of a DWH in this application domain are:
- Improving the production process to minimize the frequency of faulty parts
- Trend/prediction analysis for durability of electric devices, which are used in the field by the customer
In both cases, the required data needs to be collected and integrated in a DWH and prepared for further data analysis tasks. Take for example the following question: “Give me the measured average temperature for a particular device for the year 2008, aggregated by the quarter.” If the average temperature is close to the maximum allowed temperature according to the device specification, durability of this device might be less, compared to using the device in other temperature ranges.
Anybody in the DWH?
The question clearly involves different kinds of data, which are relevant for data analysis tasks. For example:
- Uniquely identifiable device across the entire system
- Measurement value type (e.g. temperature, current, voltage)
- Measured value (e.g. 60 degree Celsius)
- Date / Time (e.g. 11.11.2007 / 15:34:32)
In a DWH, this will be modeled as a so-called star schema, which is illustrated in 1.
Figure 1: Star-Schema
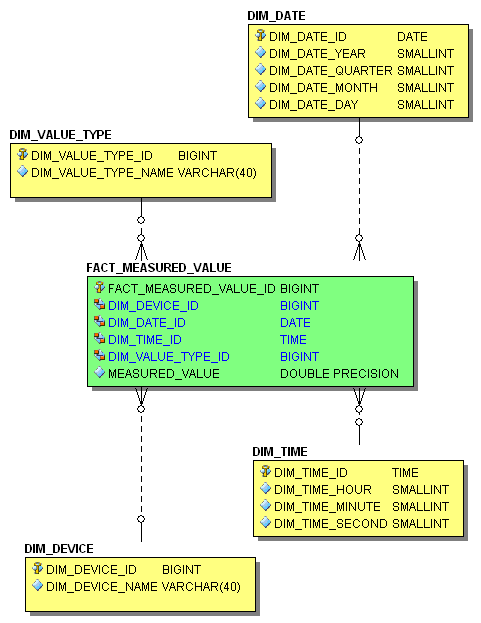
The tables used are described in the following 1.
| Table | Usage |
|---|---|
| DIM_DATE | Dimension table Date. One record is a valid date with a year, quarter, month and day. |
| DIM_TIME | Dimension table Time. One record is a valid time with an hour, minute and second. |
| DIM_DEVICE | Dimension table Device. One record uniquely identifies a device in the DWH. |
| DIM_VALUE_TYPE | Dimension table measurement value type. One record is a type of measurement value. For example: temperature, current or voltage. |
| FACT_MEASURED_VALUE | Fact table. Stores the factum/measure, which needs to be analyzed. In our case this is a measured value of a particular type (DIM_VALUE_TYPE_ID) for a particular device (DIM_DEVICE_ID) at a specific timestamp (DIM_DATE_ID and DIM_TIME_ID). |
The requirements on an OLTP and OLAP database usually differ in respect to the number of concurrent connections, availability and configuration, so both systems are operated with their own separate databases. Loading the dimension tables and the fact table is done with an ETL (extraction, transformation, loading) process, which extracts the necessary data from the OLTP system, transforms the data based on defined rules for the target system und loads the data into the OLAP database.
In this example, I have not implemented an ETL process, but Open Source products, like Kettle [4], are available for that also. For this article, a configurable loading of the dimension tables and the fact table is done with Firebird stored procedures. You will find them in Appendix 1. To get a meaningful answer in respect to the execution time and the Non-Indexed vs. Index-Reads with and without aggregate tables, at least the fact table FACT_MEASURED_VALUE must be loaded with a substantial number of records. Figure 1: Star-Schema shows the result after loading data into our OLAP database.
| Table | Usage | Stored Procedure in Appendix 1 |
|---|---|---|
| DIM_DATE | Loading for the year 2008. records => 366. |
P_LOAD_DIM_DATE |
| DIM_TIME | Loading for a day with second being the smallest unit. records => 24 * 60 * 60 = 86.400 |
P_LOAD_DIM_TIME |
| DIM_DEVICE | Three devices. records => 3 |
P_LOAD_DIM_DEVICE |
| DIM_VALUE_TYPE | Three measurement value types: voltage, current and temperature. records => 3 |
P_LOAD_DIM_VALUE_TYPE |
| FACT_MEASURED_VALUE | For the entire year 2008, for every minute a record with a measured value will be generated for each device and each measurement value type. records => 366 * 24 * 60 * 3 * 3 = 4.743.360 |
P_LOAD_FACT_MEASURED_VALUE |
To answer the question described above, a database developer can formulate an appropriate SQL query against the OLAP database or one can use an OLAP client application, which allows the query to be defined in a visual way through user interaction. The user is able to drill-down through the device and date dimensions to “navigate” to the expected result. This can be accomplished, for example, with a JPivot-based web application as shown in Figure 1: Star-Schema.
Figure 2: JPivot-based web application
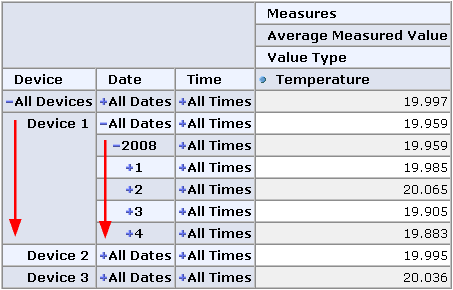
The red arrows show the possible navigation path in both dimensions. By using the activated statement tracing in Mondrian, the executed SQL statements can be identified pretty quickly. Without using any aggregate tables, the SQL statement looks like:
select
"DIM_VALUE_TYPE"."DIM_VALUE_TYPE_NAME" as "c0",
"DIM_DATE"."DIM_DATE_YEAR" as "c1",
"DIM_DATE"."DIM_DATE_QUARTER" as "c2",
"DIM_DEVICE"."DIM_DEVICE_NAME" as "c3",
avg("FACT_MEASURED_VALUE"."MEASURED_VALUE")
as "m0"
from
"DIM_VALUE_TYPE" "DIM_VALUE_TYPE",
"FACT_MEASURED_VALUE" "FACT_MEASURED_VALUE",
"DIM_DATE" "DIM_DATE",
"DIM_DEVICE" "DIM_DEVICE"
where
"FACT_MEASURED_VALUE"."DIM_VALUE_TYPE_ID"
= "DIM_VALUE_TYPE"."DIM_VALUE_TYPE_ID" and
"DIM_VALUE_TYPE"."DIM_VALUE_TYPE_NAME" = 'Temperature'
and "FACT_MEASURED_VALUE"."DIM_DATE_ID"
= "DIM_DATE"."DIM_DATE_ID"
and "DIM_DATE"."DIM_DATE_YEAR" = 2008
and
"FACT_MEASURED_VALUE"."DIM_DEVICE_ID"
= "DIM_DEVICE"."DIM_DEVICE_ID"
and
"DIM_DEVICE"."DIM_DEVICE_NAME" = 'Device 1'
group by
"DIM_VALUE_TYPE"."DIM_VALUE_TYPE_NAME",
"DIM_DATE"."DIM_DATE_YEAR",
"DIM_DATE"."DIM_DATE_QUARTER",
"DIM_DEVICE"."DIM_DEVICE_NAME"
Listing 1: OLAP SQL query without aggregate table usage
If I execute the SQL statement in a tool with my Desktop-PC, then I get the result back in approx. 1 minute and 17 seconds. The indexed vs. non-indexed reads for this SQL query in Figure 1: Star-Schema 3 show an interesting result, namely a lot of indexed-reads on different tables. The DBMS has quite some work to do to return the expected result set.
Figure 3: Indexed vs. Non-Indexed reads without aggregate table

Aggregate tables as afterburner
The concept of an aggregate table is not a new development in the area of database technologies. “Enterprise-capable” DBMSs like Oracle, DB2 or Microsoft SQL Server support the persistence of a result set from a query, including different update strategies, in the event that the data in the base-table(s) changes. DBMS vendors often refer to this as Materialized Views or Indexed Views. In this article, I will use the term “aggregate table”, unless I am referring to a DBMS-specific implementation.
The main task of an aggregate table, based on an access pattern, is to store the result set in a physical table with far fewer records than the base table. In our case, the access pattern is the aggregation of the fact table through the date dimension down to the quarter level. Furthermore, perhaps an additional requirement exists from the QA department that queries down to the month level should run with good performance as well. The aggregate schema required for this is shown in Figure 1: Star-Schema.
Figure 4: Aggregate Schema
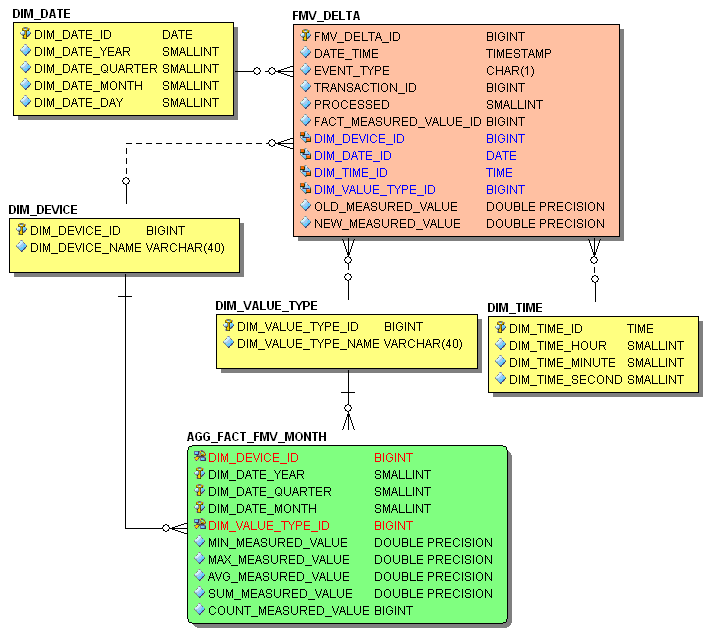
The aggregate table AGG_FACT_FMV_MONTH is a slightly changed version of your fact table from the star-schema. The date dimension down to the month level is collapsed into the aggregate table and is not referenced by a foreign key constraint to the dimension table DIM_DATE anymore. Additionally, the pre-calculated aggregates MIN, MAX, AVG, SUM and the number of relevant records are stored in the aggregate table as well. The table FMV_DELTA is dealt with later, when different loading and update strategies of the aggregate table are discussed. For the time being, we simply assume a correctly loaded aggregate table. The performance when using the aggregate table to answer the same question now looks much more promising. The following listing shows the executed SQL statement.
select
"DIM_VALUE_TYPE"."DIM_VALUE_TYPE_NAME" as "c0",
"AGG_FACT_FMV_MONTH"."DIM_DATE_YEAR" as "c1",
"AGG_FACT_FMV_MONTH"."DIM_DATE_QUARTER" as "c2",
"DIM_DEVICE"."DIM_DEVICE_NAME" as "c3",
sum("AGG_FACT_FMV_MONTH"."AVG_MEASURED_VALUE"
* "AGG_FACT_FMV_MONTH"."COUNT_MEASURED_VALUE")
/ sum("AGG_FACT_FMV_MONTH"."COUNT_MEASURED_VALUE")
as "m0"
from
"DIM_VALUE_TYPE" "DIM_VALUE_TYPE",
"AGG_FACT_FMV_MONTH" "AGG_FACT_FMV_MONTH",
"DIM_DEVICE" "DIM_DEVICE"
where
"AGG_FACT_FMV_MONTH"."DIM_VALUE_TYPE_ID"
= "DIM_VALUE_TYPE"."DIM_VALUE_TYPE_ID"
and
"DIM_VALUE_TYPE"."DIM_VALUE_TYPE_NAME"
= 'Temperature'
and
"AGG_FACT_FMV_MONTH"."DIM_DATE_YEAR" = 2008
and "AGG_FACT_FMV_MONTH"."DIM_DEVICE_ID"
= "DIM_DEVICE"."DIM_DEVICE_ID"
and
"DIM_DEVICE"."DIM_DEVICE_NAME" = 'Device 1'
group by
"DIM_VALUE_TYPE"."DIM_VALUE_TYPE_NAME",
"AGG_FACT_FMV_MONTH"."DIM_DATE_YEAR",
"AGG_FACT_FMV_MONTH"."DIM_DATE_QUARTER",
"DIM_DEVICE"."DIM_DEVICE_NAME"
Listing 2: OLAP SQL query with aggregate table usage
As you can see, the aggregate table AGG_FACT_FMV_MONTH and not the fact table FACT_MEASURED_VALUE is now used to get the expected result set, for the same drill-down user interaction. This SQL statement executed with a tool shows that the result set is returned in 30 milliseconds. The dramatically decreased number of reads is shown in Figure 1: Star-Schema.
Figure 5: Indexed vs. Non-Indexed reads with aggregate table

Not a big surprise though, because the aggregate table holds only 12 * 3 * 3 = 108 records compared to 4.743.360 records in the fact table. This is a very beneficial optimization for this particular OLAP scenario.
Query Rewriting
Mondrian needs to know in the OLAP cube definition file that an aggregate table exists for the fact table. If this definition has been done properly, the OLAP server is able to transform the initial query so that the aggregate table and not the fact table will be queried. This mechanism is called Query Rewriting, which is an important component when using aggregate tables, because it ensures transparency for the user when using an OLAP client. The user should not need to know that there is an aggregate table. He/she simply fires off an OLAP query via a user-friendly OLAP client application and the OLAP server takes care of choosing the appropriate aggregate or fact table(s) for processing the query. If this component is clever, it can use an aggregate table even if there is no 1:1 mapping between the aggregated query and an existing aggregate table. For example, Mondrian is able to use our month-based aggregate table to carry out a quarter-based OLAP query.
If query rewriting is not supported by the OLAP server, then the usage of an aggregate table is not transparent to the user, because the user needs to know which aggregate tables exist in order to formulate the correct query. Be aware that many DBMS vendors support query rewriting in their high-priced “Enterprise-capable” editions only, even if they support materialized or indexed views in their less expensive editions!
Firebird as a DBMS does not support query rewriting at all. In our DWH architecture, another component is responsible for that, namely Mondrian. The user does not need to know about the existence of aggregate tables. Mondrian handles that behind the scenes.
Update strategies
With a well-designed aggregate schema, you can achieve a high performance gain, but, some compromise is necessary, because it doesn’t make sense to create an aggregate table for each possible query in your DWH environment. For example, you might choose to concentrate on the most used OLAP queries and improve their performance with aggregate tables first. Simply create your aggregate schema driven by real-use requirements.
With the introduction of aggregate tables, one is confronted with one topic pretty quickly, namely redundancy. In the case of aggregate tables, possibly the most important factor is whether pre-aggregated data is as up-to-date as the on-the-fly aggregate calculation of a query against the fact table. If data in the fact table gets changed, pre-aggregated data in an aggregate table is out-dated automatically. As a result, querying an aggregate table might produce a different result set than querying the fact table. Primarily, there are three different update strategies discussed in the literature and used in real-life DWH environments: Snapshot, Eager and Lazy.
When using the snapshot strategy, data in the aggregate table gets fully rebuilt by deleting and re-inserting records with up-to-date aggregations. The implementation of this strategy is very simple, but server utilization during a snapshot load increases with the number of records in the fact table. A snapshot load is usually done periodically, for example after loading the fact table with an ETL process. Starting a snapshot load could be the last action in an ETL process. For instance, a call of a Firebird stored procedure, which implements the snapshot load. You will find an example in Appendix 2.
For the eager strategy, there is a delete/insert/update trigger on the fact table for each dependent aggregate table, which basically has some logic in place to re-calculate aggregates incrementally (some kind of “delta” mechanism). The aggregate table does not need to be re-built from scratch every time, but the trigger simply updates the existing pre-aggregated values with the new values from the fact table accordingly. The implementation of this strategy is more complex, but still possible. A disadvantage of this approach is that the execution time of the ETL process is slower, because with each COMMIT the trigger on the fact table gets fired. The main advantage is that pre-aggregated data is always in-sync with the fact table. The involved database objects (trigger, stored procedure) for an eager implementation are illustrated in Appendix 3.
The lazy approach has one trigger on the fact table, which logs any data changes on the fact table into a separate table (see table FMV_DELTA in Figure 1: Star-Schema 4). Periodically, a stored procedure processes the log table and for each non-processed record, the eager mechanism gets executed. With this approach, there are again additional write operations necessary, namely into the log table, but the incremental update of pre-aggregated data can be done at a later, possibly better point of time. This approach is a mixture of the other two in respect to up-to-date data in the aggregate table(s) and server utilization. The log trigger on the fact table and the stored procedure processing the log table and executing the eager update strategy can be found in Appendix 4.
Conclusion
Aggregate tables are a very interesting possibility to dramatically reduce the response time of aggregate queries in OLAP scenarios. DBMSs like Oracle, DB2 and Microsoft SQL Server have implementations for aggregate tables called Materialized or Indexed Views. Firebird currently (Version 2.1 or Version 2.5 RC) does not have a comparable feature, but with support for triggers and stored procedures, Firebird can serve as a DBMS for a hand-made aggregate table implementation, including all three update strategies mentioned above. One gets an aggregate schema which has data redundancies, but they are all controllable. In combination with an OLAP server like Mondrian with support for query rewriting, a low-cost DWH system can be built entirely on top of Open Source software, which is suitable even for larger DWH projects.
Thomas Steinmaurer is an Industrial Researcher at the Software Competence Center Hagenberg [5] (Austria) in the area of data management and data warehousing specialized for the industrial manufacturing domain. Furthermore, he is responsible for the LogManager series (an auditing solution for various DBMS backends) and Firebird Trace Manager at Upscene Productions [6] and was a co-founder of the Firebird Foundation [7] . The author can be reached at thomas.steinmaurer@scch.at or t.steinmaurer@upscene.com.
References:
Appendix 1 – Stored procedures for generating dimension and fact data
SET TERM ^^ ;
CREATE PROCEDURE P_LOAD_DIM_DATE (
START_DATE Date,
END_DATE Date,
DELETE_DIM_TABLE SmallInt DEFAULT 1)
AS
declare variable vDate Date;
declare variable vCount Integer;
declare variable vMaxCount Integer;
begin
if (delete_dim_table = 1) then
begin
delete from dim_date;
end
vDate = start_date;
vCount = 1;
vMaxCount = end_date - start_date + 1;
while (vCount <= vMaxCount) do
begin
insert into dim_date (
dim_date_id
, dim_date_year
, dim_date_quarter
, dim_date_month
, dim_date_day
) values (
:vDate
, extract(year from :vDate)
, (extract(month from :vDate) - 1) / 3 + 1
, extract(month from :vDate)
, extract(day from :vDate)
);
vDate = vDate + 1;
vCount = vCount + 1;
end
end ^^
SET TERM ; ^^
SET TERM ^^ ;
CREATE PROCEDURE P_LOAD_DIM_TIME (
DELETE_DIM_TABLE SmallInt DEFAULT 1)
AS
declare variable vTime Time;
declare variable vCount Integer;
declare variable vMaxCount Integer;
begin
if (delete_dim_table = 1) then
begin
delete from dim_time;
end
vTime = '00:00:00';
vCount = 1;
vMaxCount = 3600 * 24;
while (vCount <= vMaxCount) do
begin
insert into dim_time (
dim_time_id
, dim_time_hour
, dim_time_minute
, dim_time_second
) values (
:vTime
, extract(hour from :vTime)
, extract(minute from :vTime)
, extract(second from :vTime)
);
vTime = vTime + 1;
vCount = vCount + 1;
end
end ^^
SET TERM ; ^^
SET TERM ^^ ;
CREATE PROCEDURE P_LOAD_DIM_DEVICE (
NUMBER_OF_RECORDS Integer,
DELETE_DIM_TABLE SmallInt DEFAULT 1)
AS
declare variable vCount Integer;
begin
if (delete_dim_table = 1) then
begin
delete from dim_device;
end
vCount = 1;
while (vCount <= number_of_records) do
begin
insert into dim_device
(dim_device_id, dim_device_name)
values
(:vCount,
'Device ' || LPAD(:vCount,
CHARACTER_LENGTH(:number_of_records),
'0'));
vCount = vCount + 1;
end
end ^^
SET TERM ; ^^
SET TERM ^^ ;
CREATE PROCEDURE P_LOAD_DIM_VALUE_TYPE (
DELETE_DIM_TABLE SmallInt DEFAULT 1)
AS
begin
if (delete_dim_table = 1) then
begin
delete from dim_value_type;
end
insert into dim_value_type
(dim_value_type_id, dim_value_type_name)
values
(1, 'Voltage');
insert into dim_value_type
(dim_value_type_id, dim_value_type_name)
values
(2, 'Current');
insert into dim_value_type
(dim_value_type_id, dim_value_type_name)
values
(3, 'Temperature');
end ^^
SET TERM ; ^^
SET TERM ^^ ;
CREATE PROCEDURE P_LOAD_FACT_MEASURED_VALUE (
NUMBER_OF_ITERATIONS Integer,
NUMBER_OF_DEVICES Integer,
START_DATE Date,
START_TIME Time,
INTERVAL_SECONDS Integer,
DELETE_FACT_TABLE SmallInt DEFAULT 0)
AS
declare variable i Integer;
declare variable j Integer;
declare variable vDateTime Timestamp;
begin
if (delete_fact_table = 1) then
begin
delete from fact_measured_value;
end
i = 1;
vDateTime = start_date + start_time;
while (i <= number_of_iterations) do
begin
j = 1;
while (j <= number_of_devices) do
begin
/* Voltage - Interval [0, 5] V */
insert into fact_measured_value
(dim_device_id, dim_date_id,
dim_time_id, dim_value_type_id, measured_value)
values (
:j,
cast(:vDateTime as date),
cast(:vDateTime as time),
1, RAND() * 5);
/* Current - Interval [4, 20] mA */
insert into fact_measured_value
(dim_device_id,
dim_date_id,
dim_time_id,
dim_value_type_id,
measured_value)
values (
:j,
cast(:vDateTime as date),
cast(:vDateTime as time),
2,
(RAND() * (20 - 4) + 4) / 1000);
/* Temperature [-30, 70] Celsius */
insert into fact_measured_value
(dim_device_id,
dim_date_id,
dim_time_id,
dim_value_type_id,
measured_value)
values (:j,
cast(:vDateTime as date),
cast(:vDateTime as time),
3,
RAND() * (70 - (-30)) + (-30));
j = j + 1;
end
vDateTime = DATEADD(SECOND, interval_seconds, vDateTime);
i = i + 1;
end
end ^^
SET TERM ; ^^
Appendix 2 – Snapshot update strategy objects
SET TERM ^^ ;
CREATE PROCEDURE P_SSLOAD_AGG_FACT_FMV_MONTH (
DELETE_TABLE SmallInt)
AS
begin
if (delete_table = 1) then
begin
delete from agg_fact_fmv_month;
end
insert into agg_fact_fmv_month
select
fmv.DIM_DEVICE_ID
, dd.dim_date_year
, dd.dim_date_quarter
, dd.dim_date_month
, fmv.DIM_VALUE_TYPE_ID
, min(fmv.MEASURED_VALUE)
, max(fmv.MEASURED_VALUE)
, avg(fmv.MEASURED_VALUE)
, sum(fmv.MEASURED_VALUE)
, count(fmv.MEASURED_VALUE)
from
fact_measured_value fmv
join dim_date dd
on (fmv.DIM_DATE_ID = dd.DIM_DATE_ID)
group by
fmv.DIM_DEVICE_ID
, dd.dim_date_year
, dd.dim_date_quarter
, dd.dim_date_month
, fmv.DIM_VALUE_TYPE_ID
;
end ^^
SET TERM ; ^^
SET TERM ^^ ;
CREATE PROCEDURE P_SSLOAD_ALL_AGG_TABLES (
DELETE_TABLE SmallInt)
AS
begin
execute procedure P_SSLOAD_AGG_FACT_FMV_MONTH(DELETE_TABLE);
end ^^
SET TERM ; ^^
Appendix 3 – Eager update strategy objects
SET TERM ^^ ;
CREATE PROCEDURE P_EAGLOAD_AGG_FACT_FMV_MONTH (
DIM_DEVICE_ID BigInt,
DIM_DATE_ID Date,
DIM_VALUE_TYPE_ID BigInt,
OLD_MEASURED_VALUE Double Precision,
NEW_MEASURED_VALUE Double Precision,
EVENT_TYPE Char(1))
AS
declare variable vMinMeasuredValue D_DOUBLE_NULL = null;
declare variable vMaxMeasuredValue D_DOUBLE_NULL = null;
declare variable vAvgMeasuredValue D_DOUBLE_NULL = null;
declare variable vSumMeasuredValue D_DOUBLE_NULL = null;
declare variable vCountMeasuredValue D_BIGINT_NULL = null;
declare variable vDimDateYear D_SMALLINT_NULL = null;
declare variable vDimDateQuarter D_SMALLINT_NULL = null;
declare variable vDimDateMonth D_SMALLINT_NULL = null;
begin
vDimDateYear = extract(year from dim_date_id);
vDimDateQuarter =
(extract(month from dim_date_id) - 1) / 3 + 1;
vDimDateMonth = extract(month from dim_date_id);
select
min_measured_value
, max_measured_value
, avg_measured_value
, sum_measured_value
, count_measured_value
from
agg_fact_fmv_month
where
dim_device_id = :dim_device_id
and dim_date_year = :vDimDateYear
and dim_date_quarter = :vDimDateQuarter
and dim_date_month = :vDimDateMonth
and dim_value_type_id = :dim_value_type_id
into
:vMinMeasuredValue
, :vMaxMeasuredValue
, :vAvgMeasuredValue
, :vSumMeasuredValue
, :vCountMeasuredValue;
if (event_type = 'I') then
begin
/* Fact record inserted */
/* COUNT */
vCountMeasuredValue = coalesce(vCountMeasuredValue, 0)
+ 1;
/* MINIMUM */
vMinMeasuredValue = MINVALUE(coalesce(vMinMeasuredValue,
new_measured_value), new_measured_value);
/* MAXIMUM */
vMaxMeasuredValue = MAXVALUE(coalesce(
vMaxMeasuredValue, new_measured_value), new_measured_value);
/* SUM */
vSumMeasuredValue = coalesce(vSumMeasuredValue, 0)
+ new_measured_value;
/* AVG */
vAvgMeasuredValue = vSumMeasuredValue / vCountMeasuredValue;
end else if ((event_type = 'D') or (event_type = 'U')) then
begin
/* Fact record deleted or updated */
/* COUNT */
if (event_type = 'D') then
begin
/* delete */
vCountMeasuredValue = vCountMeasuredValue - 1;
/* If event_type ='U' => vCountMeasuredValue
stays equal */
end
if (vCountMeasuredValue > 0) then
begin
/* MINIMUM / MAXIMUM */
if ((vMinMeasuredValue = old_measured_value)
or (vMaxMeasuredValue = old_measured_value)) then
begin
/* If a fact record is delete or updated, which
measured_value is either the */
/* minimum or maximum */
/* => re-calculate MIN/MAX */
select
min(fmv.measured_value)
, max(fmv.measured_value)
from
fact_measured_value fmv join dim_date d
on (fmv.dim_date_id = d.dim_date_id)
where
fmv.dim_device_id = :dim_device_id
and d.dim_date_year = :vDimDateYear
and d.dim_date_quarter = :vDimDateQuarter
and d.dim_date_month = :vDimDateMonth
and fmv.dim_value_type_id = :dim_value_type_id
into
:vMinMeasuredValue
, :vMaxMeasuredValue;
end
/* SUM */
if (event_type = 'D') then
begin
/* delete */
vSumMeasuredValue = vSumMeasuredValue
- old_measured_value;
end else
begin
/* update */
vSumMeasuredValue = vSumMeasuredValue
+ (new_measured_value - old_measured_value);
end
/* AVG */
vAvgMeasuredValue = vSumMeasuredValue
/ vCountMeasuredValue;
end
end
/* Refresh the aggregate table */
if (vCountMeasuredValue > 0) then
begin
/* Update existing or insert new record
into aggregate table */
update or insert into agg_fact_fmv_month (
dim_device_id
, dim_date_year
, dim_date_quarter
, dim_date_month
, dim_value_type_id
, min_measured_value
, max_measured_value
, avg_measured_value
, sum_measured_value
, count_measured_value
) values (
:dim_device_id
, :vDimDateYear
, :vDimDateQuarter
, :vDimDateMonth
, :dim_value_type_id
, :vMinMeasuredValue
, :vMaxMeasuredValue
, :vAvgMeasuredValue
, :vSumMeasuredValue
, :vCountMeasuredValue
);
end else
begin
/* No more fact table record for the particular aggregate exists */
/* => delete aggregated record */
delete from
agg_fact_fmv_month
where
dim_device_id = :dim_device_id
and dim_date_year = :vDimDateYear
and dim_date_quarter = :vDimDateQuarter
and dim_date_month = :vDimDateMonth
and dim_value_type_id = :dim_value_type_id;
end
end ^^
SET TERM ; ^^
SET TERM ^^ ;
CREATE TRIGGER TR_FMV_AGG_FACT_FMV_MONTH
FOR FACT_MEASURED_VALUE
ACTIVE AFTER INSERT OR UPDATE OR DELETE
POSITION 1000
AS
declare variable vEventType CHAR(1);
declare variable vOldMeasuredValue D_DOUBLE_NULL;
declare variable vNewMeasuredValue D_DOUBLE_NULL;
declare variable vDimDeviceId Bigint;
declare variable vDimDateId Date;
declare variable vDimValueTypeId Bigint;
begin
if (DELETING) then
begin
vEventType = 'D';
vDimDeviceId = old.dim_device_id;
vDimDateId = old.dim_date_id;
vDimValueTypeId = old.dim_value_type_id;
vOldMeasuredValue = old.measured_value;
vNewMeasuredValue = null;
end else if (INSERTING) then
begin
vEventType = 'I';
vDimDeviceId = new.dim_device_id;
vDimDateId = new.dim_date_id;
vDimValueTypeId = new.dim_value_type_id;
vOldMeasuredValue = null;
vNewMeasuredValue = new.measured_value;
end else if (UPDATING) then
begin
vEventType = 'U';
vDimDeviceId = new.dim_device_id;
vDimDateId = new.dim_date_id;
vDimValueTypeId = new.dim_value_type_id;
vOldMeasuredValue = old.measured_value;
vNewMeasuredValue = new.measured_value;
end
execute procedure p_eagload_agg_fact_fmv_month (
:vDimDeviceId
, :vDimDateId
, :vDimValueTypeId
, :vOldMeasuredValue
, :vNewMeasuredValue
, :vEventType
);
end ^^
SET TERM ; ^^
Appendix 4 – Lazy update strategy objects
SET TERM ^^ ;
CREATE TRIGGER TR_FMV_FMV_DELTA FOR FACT_MEASURED_VALUE
ACTIVE AFTER INSERT OR UPDATE OR DELETE POSITION 31000
AS
declare variable vFactMeasuredValueId D_IDREF_NOTNULL;
declare variable vDimDeviceId D_IDREF_NOTNULL;
declare variable vDimDateId D_DATE_NOTNULL;
declare variable vDimTimeId D_TIME_NOTNULL;
declare variable vDimValueTypeId D_IDREF_NOTNULL;
declare variable vOldMeasuredValue D_DOUBLE_NULL;
declare variable vNewMeasuredValue D_DOUBLE_NULL;
declare variable vEventType D_CHAR_1_NOTNULL;
begin
if (DELETING) then
begin
vEventType = 'D';
vFactMeasuredValueId = old.fact_measured_value_id;
vDimDeviceId = old.dim_device_id;
vDimDateId = old.dim_date_id;
vDimTimeId = old.dim_time_id;
vDimValueTypeId = old.dim_value_type_id;
vOldMeasuredValue = old.measured_value;
vNewMeasuredValue = null;
end else if (INSERTING) then
begin
vEventType = 'I';
vFactMeasuredValueId = new.fact_measured_value_id;
vDimDeviceId = new.dim_device_id;
vDimDateId = new.dim_date_id;
vDimTimeId = new.dim_time_id;
vDimValueTypeId = new.dim_value_type_id;
vOldMeasuredValue = null;
vNewMeasuredValue = new.measured_value;
end else if (UPDATING) then
begin
vEventType = 'U';
vFactMeasuredValueId = new.fact_measured_value_id;
vDimDeviceId = new.dim_device_id;
vDimDateId = new.dim_date_id;
vDimTimeId = new.dim_time_id;
vDimValueTypeId = new.dim_value_type_id;
vOldMeasuredValue = old.measured_value;
vNewMeasuredValue = new.measured_value;
end
insert into fmv_delta (
event_type
, fact_measured_value_id
, dim_device_id
, dim_date_id
, dim_time_id
, dim_value_type_id
, old_measured_value
, new_measured_value
) values (
:vEventType
, :vFactMeasuredValueId
, :vDimDeviceId
, :vDimDateId
, :vDimTimeId
, :vDimValueTypeId
, :vOldMeasuredValue
, :vNewMeasuredValue
);
end ^^
SET TERM ; ^^
SET TERM ^^ ;
CREATE PROCEDURE P_LAZYLOAD_ALL_AGG_TABLES (
DELETE_PROCESSED_RECORDS SmallInt)
AS
declare variable vFactMeasuredValueId D_IDREF_NOTNULL;
declare variable vDimDeviceId D_IDREF_NOTNULL;
declare variable vDimDateId D_DATE_NOTNULL;
declare variable vDimTimeId D_TIME_NOTNULL;
declare variable vDimValueTypeId D_IDREF_NOTNULL;
declare variable vOldMeasuredValue D_DOUBLE_NULL;
declare variable vNewMeasuredValue D_DOUBLE_NULL;
declare variable vFmvDeltaId D_ID;
declare variable vEventType D_CHAR_1_NOTNULL;
declare variable vMinFmvDeltaId Bigint = null;
declare variable vMaxFmvDeltaId Bigint = null;
begin
for
select
d.FACT_MEASURED_VALUE_ID
, d.dim_device_id
, d.dim_date_id
, d.dim_time_id
, d.dim_value_type_id
, d.FMV_DELTA_ID
, d.EVENT_TYPE
, d.OLD_MEASURED_VALUE
, d.NEW_MEASURED_VALUE
from
fmv_delta d
where
d.processed = 0
order by
d.FMV_DELTA_ID
into
:vFactMeasuredValueId
, :vDimDeviceId
, :vDimDateId
, :vDimTimeId
, :vDimValueTypeId
, :vFmvDeltaId
, :vEventType
, :vOldMeasuredValue
, :vNewMeasuredValue
do
begin
if (vMinFmvDeltaId is null) then
begin
vMinFmvDeltaId = vFmvDeltaId;
end
vMaxFmvDeltaId = vFmvDeltaId;
/* Eager load on MONTH aggregate table */
execute procedure P_EAGLOAD_AGG_FACT_FMV_MONTH (
:vDimDeviceId
, :vDimDateId
, :vDimValueTypeId
, :vOldMeasuredValue
, :vNewMeasuredValue
, :vEventType
);
end
if (delete_processed_records = 1) then
begin
/* Delete all processed records in FMV_DELTA
identified via an */
/* interval of primary key values. */
delete from
fmv_delta d
where
d.FMV_DELTA_ID between :vMinFmvDeltaId
and :vMaxFmvDeltaId;
end else
begin
/* Update all processed records in FMV_DELTA
identified via an */
/* interval of primary key values. */
update
fmv_delta d
set
d.processed = 1
where
d.FMV_DELTA_ID between :vMinFmvDeltaId
and :vMaxFmvDeltaId;
end
end ^^
SET TERM ; ^^