by Pavel Císař
Introduction
Transaction processing is often cited as a greatest asset of database systems, and is a strong argument to stop using “flat-file” databases and change to one of a wide range of more “modern” systems because of the significant safety improvements that are available for stored data. Since relational database systems with transaction processing support such as Firebird are very common, are cheap and easily accessible from almost any programming language or environment. Because there is no reason to carry on using DBF, Paradox or Access databases, many developers have already made this transition.
Although transactions are usually explained in the documentation for any particular SQL server, and this topic is also typically discussed in many books and papers. It is therefore surprising that a large number of database applications that use transactions do not perform well. Why? Because these applications are usually not designed and implemented in accordance with the specifics of transaction processing, and do not always take into account the subtle implementation differences that exist in each database system.
This could be due to the need to implement new and improved software faster, which then usually has a detrimental effect on careful application design. It could also be due to a lack of documentation that would offer a deeper insight into transaction processing in wider context. But is actually often caused by the usage of modern development tools and libraries that successfully isolate developers from what are seen as “needless details”, and therefore remove the need for a developer to really understand what is actually happening in an application. Although anyone can now use transactions, thanks to the very simple programming interface they usually have not all developers have a deeper understanding of how transactions really work in the database system that they use.
The purpose of this particular paper is to offer a detailed explanation of transaction processing in Firebird, along with all the details related to its implementation, and also put it in a wider context in relation to implementations that are used in other relational database systems.
Introduction to transaction processing
When developers who are more used to flat-file databases, and are then introduced to the advantages of transactions, they often believe that main purpose of transaction processing is to save them from data loss or corruption in case of hardware or software malfunction. This somewhat oversimplified view about transactions is misleading. It’s true that transactions can minimise the impact of such a failure in most cases, but this is more of a side effect, because the sole purpose of transaction processing is to ensure data integrity, nothing more and nothing less.
In fact, transaction processing is a general concept, whose purpose is to ensure integrity of any dynamic system in the course of transition from one consistent state to another. Where the consistent state is any system’s state that is pertinent to the definition of the allowed system states for each system part, and adheres to the rules that govern their mutual relations.
So transactions are not specific to just database systems, they can be found in other dynamic systems as well, but because databases are dynamic systems, it’s natural that database management systems have support for transaction processing to ensure the integrity of the data that is kept in the database.
The philosophy of transactions in database systems is built on premise that the picture of the real world as represented by stored data, is consistent to specific rules (for example uniqueness, relationships between values on rows or between tables, and other constraints) that are defined at the database design stage in a so-called data model. Data in a database is usually not static, and undergoes transformations represented by an exact sequence of operations that add, update or delete values in database. Transaction is the commonly used name for such a transformation sequence. There is typically a lot of correct transformations and a list of the most important transformations (at least all transformations performed by clients) should be a part of any proper database design.
Support for transaction processing in database management systems like Firebird, is just a set of tools and methods that perform data transformations/transactions in a way that ensures that the data will remain consistent even in case of failure on the client or server side. By this the data will be in the same state as it was before the transaction started. This works only if all of the following conditions are met:
- Consistent states are properly defined. No database management system can identify these states by itself. In fact, the state of the database after each successfully committed transaction is considered as consistent, regardless or whether you think it’s true or not from your point of view.
- Individual transactions are properly defined. The developer, not the database system or application, is responsible for defining the proper sequence of operations that make up a transaction.
- Transactions are correctly processed. The database system must be informed when a transaction starts and ends, otherwise it’s not able to ensure its validity.
As you can see, transaction processing is built on top of various abstractions without a default behaviour, and it’s up to you as a developer to define that behaviour. A badly designed database or application can defeat the whole system, and negate all the advantages that come from the correct usage of transaction processing.
Because data consistency is ensured by fall-back (called rollback) to the previous state every time the transaction could not be successfully ended (committed), transaction processing is often explained and understand as collection of “changes” that are written permanently to the database after a successful commit. This is yet another simplified explanation that is a potential source of trouble for developers introduced to transactions, because a typical implementation (including the one used by Firebird) writes all the changes immediately to the database, along with information needed to restore it to its previous state. This approach has several important implications, where the most important one is the impact on the simultaneous work of multiple users (it will be discussed later in detail). Another implication is that after a failure, a database may contain “garbage” from unfinished transactions represented by actual changes and auxiliary data structures used by server itself, that then need to be cleaned or fixed.
While transaction processing systems are designed in a way that ensures that any client’s failure will not corrupt the database, when failure happens on server it’s not guaranteed that the database will not be corrupted. Although database servers are carefully designed to minimise the danger of database corruption in case of their abnormal termination, you should always expect the worst case when such a failure happens. So you should look at taking other safety precautions on your database server, such as UPS, and regular backups and database validation.
Basic requirements for transaction processing
The basic requirements for maintaining integrity in a database that is used in a parallel read, write environment are summarised into four precepts widely known under their abbreviated acronym as ACID transaction properties. These basic requirements are:
Atomicity.
All data-transforming operations performed within single transaction are realised as a single indivisible operation.
Consistency.
Database could be in inconsistent state during the course of a running transaction, but when a transaction successfully completes, the final database state must be consistent.
Isolation.
Each transaction must be completely isolated from other concurrently running transactions, so any transient data transformations are not exposed to other transactions before the transaction completes.
Durability.
After and only after the transaction successfully completes, all the data transformations are made permanent.
At the first glance, these functional requirements are clear and simple, but the reality is quite different. Let’s look at their real impact on database management systems and possible strategies for their implementation.
Atomicity
For developers, atomicity is the corner stone and the most visible pillar of transaction processing, this attribute ensures that associated data changes (like money transferred between accounts) are always performed correctly. Unfinished associated updates are a nightmare for developers working with flat-file databases systems, and thus atomicity in itself is a strong enough argument to switch over to a database system with transaction support.
Atomicity is also the usual starting point for developers that design and implement database management systems, because the decision on how it will be implemented also determines the possible ways for the implementation of other transaction attributes. Database management systems implement atomicity as an ability to automatically restore the database to its original state before a transaction’s start in case of failure, or intentional transaction cancellation during any operation. It may seem (especially when you take into account the definition of Durability) that the simplest way to implement this functionality is to hold all pending changes in memory and then write them to database on commit.
While it looks like the simplest way to achieve atomicity (and durability), it will not save you from the problems in implementing database writes in such a way that they are safe from unexpected failures, and it also complicates the implementation of data retrieval in multi-user environment. Especially if you consider that in real world applications almost all transactions are always successfully committed. As such the database can’t efficiently use such an ability to quickly recover to a previous state, it needs too much work and requires a lot of complicated code for almost no gain.
Instead of keeping pending changes in memory, almost all database systems write all the changes immediately to the database, along with information necessary for the database to restore itself into a previous state. But this approach also has a drawback, busy systems can generate a lot of recovery information that must be stored on disk. On the other side, this information is transient by nature, because when data is successfully committed, it’s not needed anymore, at least for the purpose of Atomicity and Durability. Hence any database system that uses this approach must also provide a mechanism to keep the growth of these recovery data structures under control.
After closer examination of the most used database systems, you will find that they use one of two basic implementation strategies.
The first strategy:
A database contains only the latest data, so updated data rows are immediately updated with new values. To restore database into previous state, the database system keeps recovery information in a special format that is typically stored in separate files known as transaction logs. Information in transaction logs can be seen as a structured stream of instruction blocks that describe operations to be performed by server on a database, to allow it to restore itself back to a specific state corresponding to some point in time. This strategy is more traditional, and is used by systems like Oracle, DB2, Sybase or MS SQLServer.
This approach has some important implications:
- A rollback is relatively “expensive” operation, and restart after an unexpected failure could take a lot of time.
- It’s possible to “unwind” changes not only from unfinished transactions, but also from committed ones if the recovery data is still available, so theoretically it’s possible to restore the database into any previous state.
- Because transient recovery data is kept separately from the main database, it’s possible to easily archive or delete outdated recovery data logs.
- It’s easy to implement incremental backups.
- The most important impact of this approach is on the implementation of Isolation. Because the database contains only the most recent snapshot of data that could be the result of changes made by concurrent transactions, it’s necessary to strictly manage access to data from separate transactions, and database systems that use this approach typically use various locking strategies to do that. More about that later.
A second strategy:
A database can contain multiple versions of data rows, so any row that is going to be updated is left intact, and a new row version is created instead of a direct row update. In this case, a transaction log containing special recovery information is not necessary, because the database in contains multiple states. This strategy is also known as Multigenerational Architecture (MGA), and was first used by InterBase (and hence it’s also used by Firebird). MGA is also used by PostgreSQL and MySQL (InnoDB).
This approach has the following important implications:
- A rollback is “cheap”, i.e. it typically consumes the same system resources as a commit.
- “Recovery information” is stored directly in the database, so the database itself is “polluted” by transient data. Although database systems that use MGA have measures to remove row versions that are no longer needed, however they typically need some “co-operation” from the application developers. More about that later.
- “Recovery information” is hard to extract and archive, so incremental backups or recovery to any point of time is hard to implement, and often not supported.
- Because the database contains multiple states of data, the implementation of Isolation has different characteristics than one that uses single data states and a transaction log, because many types of collisions between read and write concurrent transactions do not happen. More about that later.
As you can see, both strategies have their strengths and weaknesses, and the initial decision about which one is used has an important impact on system characteristics.
Consistency
Consistency is a somewhat troublesome attribute. Most database systems (especially those based on SQL) offer either more or less complex system’s designed to ensure the consistency of data in the database. This system typically allows you to define check conditions for table columns, data relationships between columns in a table row, and relationships between tables (referential constraints). It’s also possible to define very complex consistency rules using triggers and stored procedures. All data operations are then checked by database system against these conditions, and if any condition is violated, it’s signalled by the database system as an error. But this violates the definition of Consistency. Which allows data inconsistencies in the course of transition from one state to another (i.e. during a transaction). Not all database systems support what are called deferred constraints, constraints that are validated only at the end of a transaction. Automatic validation of data consistency constraints also has a negative influence on a system’s performance and resource consumption.
Many real-world applications tend to use a compromise solution that uses partial or full implementation of data consistency checks in the client application, and carefully designed transactions. This approach works best in cases when data is manipulated only from client applications that you can control. Automatic data consistency constraints enforced by database system itself, are best for situations where clients use various methods and applications for database access. But whatever approaches you use in your application to ensure data consistency, your data would be consistent only in so far and how well you will design and implement your system.
As you can see, Consistency is not real, its only a supposed transaction attribute. The actual realistaion of it, is always up to you!
Isolation
Isolation is the most complicated transaction attribute, and it’s the source of serious trouble for many developers. The purpose of Isolation is to prevent interference between concurrent transactions that would lead into data loss or incorrect data interpretation or calculations. In summary, they are:
Lost updates, that would occur when two users have the same view of a set of data and one user performs changes, closely followed by the other user, who then overwrites the first user's work.
Dirty reads, that permit one user to see the changes that another user is in the process of doing, with no guarantee that the other user's changes are final.
Non-reproducible reads, that allow one user to select rows continually while other users are updating and deleting. Whether this is a real problem depends on the circumstances. For example, a month-end financials process or a snapshot inventory audit will be skewed under these conditions, versus for example a ticketing application that needs to keep all users' views synchronised to avoid double booking.
Phantom rows, which arise when one user can select some but not all the new rows written by another user. This may also be acceptable in some situations but will skew the outcomes of some processes.
Interleaved transactions. These can arise when changes in one row by one user affects the data in other rows in the same table or in other tables being accessed by other users. They are usually timing-related, occurring when there is no way to control or predict the sequence in which users perform the changes.
To prevent these issues, the database system must:
- Protect all data read by a transaction from changes by other transactions.
- Ensure that data read by a transaction can also be changed by this transaction.
- Ensure that pending changes made by a transaction will not be accessible to other transactions.
Which can be translated into a single general requirement that: a write operation from one transaction must be mutually exclusive with any other operation (including read) on the same data from other transactions.
The implementation of data access synchronisation is determined by the method used for the implementation of Atomicity.
Database systems that use a single state database with transaction logs must use locks on data in the database. These locks are typically applied on individual rows to reduce contention between transactions, and are promoted to locks on larger structures like database pages or tables when necessary (for example when the number of row locks on single page or table exceeds a pre-defined limit, these locks are then promoted to page or table locks to save system resources). The locking mechanism used in these databases is quite complicated, and is beyond the scope of this paper.
Database systems with MGA also use locks, but in a different way than the previously described systems. They don’t need to protect readers by “locking” all attempts to write from other transactions, because the old data values are still present in the database as old row versions, and are thus available for readers. They also don’t need separate locks to protect writes from overwriting, because this requirement can be determined from the existence of row versions. These systems use locks only in special cases, that can not be resolved in other way (e.g. when it is necessary to ensure that once read data could be also updateable).
As you can see, MGA has better potential to provide higher concurrency, but both architectures have a basic problem with data access serialisation if they fulfil the general requirement that a write operation from one transaction must be mutually exclusive with any operation on the same data from other transactions. Moving the serialisation down from database level to row, database page or table level can reduce contention between transactions if they operate in different parts of database, but it also creates room for deadlocks.
There is no good solution to this problem other than a compromise between data consistency and concurrency. This may look strange, but in fact, many database operations do not have such high requirements on isolation from other transactions, and database systems typically offer various levels of compromise between maximum concurrency and data consistency, so you can pick one that best fits your needs. These “compromises” are known as Isolation levels. An Isolation level is an attribute of an individual transaction, and there could be multiple transactions running concurrently, all with different isolation levels.
Isolation levels are defined by SQL standard, but they were introduced to database systems before first version of this standard was created, so different databases often use different isolation level names, or the functional characteristics of the implemented isolation levels can differ from those defined by standard. To make this situation even worse, isolation levels defined by standard are specified by implementations that do not use MGA.
The SQL standard defines four transaction isolation levels: Read Uncommitted, Read Committed, Repeatable Read and Serializable. The standard requires that any database system must implement Read Committed and Serializable isolation levels, while the other two are optional.
All isolation levels provide protection from Lost updates, i.e. collisions between writers. The way that they differ from each other is in how they handle other concurrency issues that come from collisions between readers and writers.
Read Uncommitted
This isolation level provides highest possible concurrency. It’s also called “Dirty Read”, because it allows transactions to see uncommitted changes from other transactions. This isolation level can be safely used by any transaction that only writes data, and doesn’t read it.
This isolation level is not supported by Firebird, because with MGA it doesn’t make sense (readers can always see older committed version of a changed row, so why read the uncommitted one?). On the other hand, it makes sense for databases that use locks, because this isolation level uses only write locks and doesn’t care about other locks, and thus has the lowest possibility for collisions with other transactions.
Read Committed
This isolation level provides the most basic data read consistency, i.e. a transaction can see only committed data, but it doesn’t protect from other read consistency issues, like Non-repeatable Read and Phantom rows. This isolation level is good for transactions that do “change monitoring” tasks, or that don’t depend on Repeatable Read.
In non-MGA database systems, Read Committed transactions are blocked on an attempt to read a row with pending changes. Firebird provides two variants of this isolation level: one that takes full advantage of MGA that reads a previous committed version of row and thus is not blocked (record_version transaction option), and second that imitates the behaviour of locking databases (no_record_version transaction option).
Repeatable Read
Like the previous isolation level, a Repeatable Read transaction reads only committed data, but also has stable view of previously read rows. The SQL standard allows Phantom rows in this isolation level, because it assumes that database system would use locks. In databases with locks, a transaction in Repeatable Read isolation places a lock on each row it reads, that then blocks other transactions that want to update or delete them, but these row locks don’t prevent other transactions inserting new rows (this would require a table lock or something similar). This use of locks has also two important implications:
- As in the Read Committed level, the transaction can’t read changed (and thus locked) rows.
- It is guaranteed that when a transaction acquires a lock on a row, it can be updated later by the same transaction.
Firebird does not have direct support for this isolation level, but provides very similar one called Snapshot (or Concurrency), because it provides a real database snapshot where a transaction once started can’t see any changes, committed or uncommitted, made by other transactions, including newly inserted rows. Because Firebird (due to MGA) doesn’t use row locks, snapshot transactions are not blocked on attempts to read rows changed by other transactions. On the other hand, without row locks Firebird can’t guarantee, that once read, rows can be also updated by the same transaction.
Serializable
This isolation level provides the total consistency required for full transaction Isolation at the expense of very poor concurrency. In the SQL standard, this level is the only one that doesn’t allow Phantom rows and Interleaved transactions to occur, which is necessary for some calculations or reports. In this isolation level, readers lock out all other possible writers, and it iss typically implemented with the use of table locks.
This level is supported by Firebird as Snapshot Table Stability (or Consistency). It’s basically the same as Snapshot level, but in addition it also guarantees that once read rows, can be also be updated. In Firebird, it is used by acquiring protected-write table locks when a table is accessed by the transaction. So any other read/write transaction is blocked access to this table.
If you don’t really need the guarantee of updateability and Interleaved transactions can’t happen thanks to strict predictable order of update operations, but you also need the absence of Phantom rows, you should use the Snapshot isolation level rather than this one.
Firebird also offers fine-grained lock control to individual tables as a Table reservation transaction option, which can be used with both Read Committed and Snapshot isolation levels to get the same effects as Snapshot Table Stability, this has the following advantages:
- Tables are locked when the transaction begins, rather than when they are first accessed by a statement. The collision resolution mode (WAIT/NOWAIT) is applied during the transaction request and any conflict with other transactions having pending updates will result in a WAIT for the handle, or a denial of the handle in the NOWAIT case. This feature of table reservation is important because it greatly reduces the possibility of deadlocks.
- Provides dependency locking, i.e. the locking of tables which might be affected by triggers and integrity constraints. Dependency locking is not normally in Firebird. However, it will ensure that update conflicts arising from indirect dependency conflicts will be avoided.
- You can lock only certain tables, or specify different access requirements for individual tables. For example, a SNAPSHOT transaction that needs sole write access to all rows in a particular table could reserve it, while assuming normal access to rows in other tables. This is a less aggressive way to apply table-level locking than the alternative, using Snapshot Table Stability isolation.
Table reservation offers four lock modes applicable for individual tables:
- Shared read. All transactions can read and update, offers most concurrency.
- Shared write. All transactions except Serializable can read and update.
- Protected read. All transactions (including this) can only read.
- Protected write. All transactions except Serializable can read, but only this transaction can write.
Interactions between isolation levels
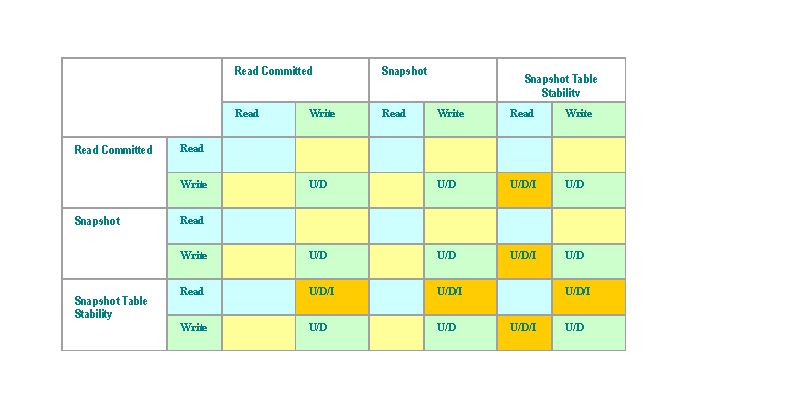
Because the isolation level is an attribute of an individual transaction, and there could be a number of concurrently running transactions using different isolation levels, it’s necessary to consider how these isolation levels interact with each other. The next two tables illustrate these interactions.
Transaction operations are divided to read (blue) and write (green). Yellow indicates interaction between read and write operations. Write operations are indicated by letters: U (update), D (delete) and I (insert).
Table 1: Collisions - SQL (and locking database) Isolation Levels
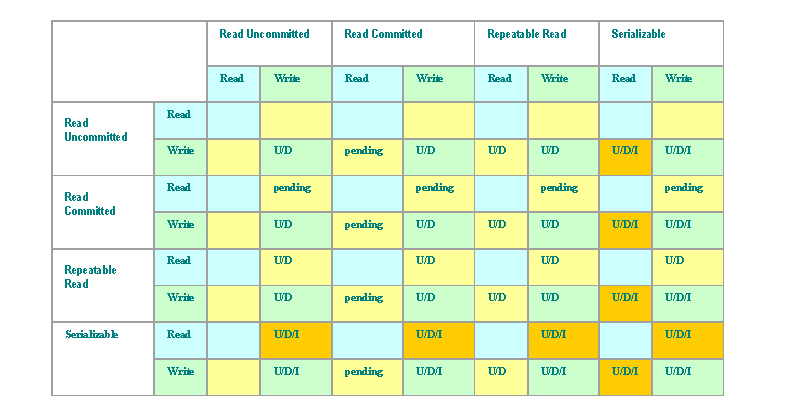
Table 2: Collisions – Firebird (and other MGA) Isolation Levels
As you can see, systems that use locks and transaction logs can have trouble with lock contention in all isolation levels (excluding Read Uncommitted) in highly concurrent environments that involve both readers and writers. But thanks to external transaction logs, they can keep internal database structures in a clean and compact state that allows for very efficient data retrieval.
Firebird and other database systems with MGA are very efficient in environments with concurrent readers and writers, because they are almost collision free, but special caution must be taken to keep the database internal structures in a clean compact state, otherwise data retrieval performance can degrade over time.
Durability
Durability of changes for successfully committed transactions is the most comprehensible transaction attribute as there is nothing special about it, except that it has a not so obvious aspect that consists of a special meaning of “commit” for database systems. Although the implementation of data persistence itself including the plumbing for rollback is typically contained in the implementation of Atomicity (data is written immediately but in “recoverable” structures to handle unexpected failures), there is still some work left that the database systems must do at commit time. A successful transaction end must be permanently registered (in the database or in other data structures written on disk), which can prove to be quite complicated e.g. if the transaction spans more than one database (requires two-phase commit protocol), or there could be also some requests from the transaction that have been deferred to commit time, like dispatching event notifications to listeners.
Implementation of transactions in Firebird
Firebird uses the Multigenerational Architecture (MGA) for its implementation of transactions, which is built on:
- The creation of versions for each data record (table row). These record versions are stored in database as linked list for each row, where the most recent record version maintains a constant position in the database. Each record version contains an identification number of the transaction that created it, and a pointer to its previous record version. A new record version is also created for deleted rows, but it’s a very small one that indicates deleted row.
- Bookkeeping of transaction states. Transaction states are stored as a bitmap indexed by transaction number, where each transaction state is encoded with two bits. To minimise memory consumption, this table doesn’t hold states for all transactions, but it’s reduced only to the range of transaction numbers starting from the oldest (with smallest transaction number) uncommitted transaction (the so called Oldest Interesting Transaction - OIT) to the most recent transaction.
- Tracking of “important” transaction numbers. Firebird transaction numbers for Next Transaction, Oldest Interesting Transaction (see above) and Oldest Active Transaction (OAT) are stored in database in the Database Header Page, and are recalculated and written whenever a new transaction is started.
Record versions
Table data is stored on a special type of database pages called Data Pages (page type 5). Each data page contains the rows for one table only, and has the following basic structure:
- Standard page header, that also contains flags signalling if the page is orphaned (lost in chain on a server crash) or also contains BLOB data or an array.
- Sequential page number (control information).
- Internal table ID (control information).
- Number of rows or row fragments on the page.
- An array of row descriptors, where each descriptor has fixed length and contains an offset to the page and data size.
- Data for individual rows.
The array of row descriptors (also called row slots) is stored at the top of page and grows to the bottom of the page. Row data is stored from the bottom and grows to the top (see next picture).
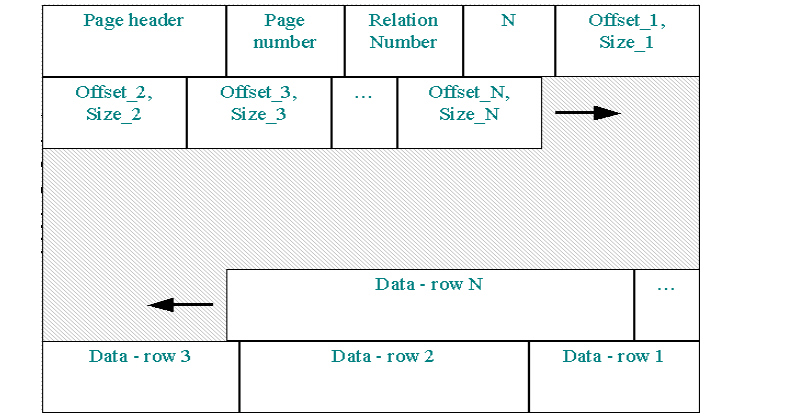
Row descriptors always point to the latest row version data block. If this data block doesn’t fit on a page, it’s split into record fragments of various lengths, and stored on more data pages. Each record version data block contains:
- Row header * Transaction number from transaction that created this record version. * Pointer to previous record version. * Flags.
- Logically deleted row.
- Old version (this version is referenced from newer version).
- Data block is only a fragment.
- Incomplete row. This is only the first fragment, others are stored elsewhere.
- This data block contains BLOB data that can be stored directly on a data page (small BLOB data is stored directly in a data block on a Data page, for larger ones the data block contains only pointers to data stored on special database pages called BLOB pages)
- Data in this version are stored as Delta’s (difference’s) from the previous version.
- Data block is corrupted (found by validation). * Row format number, identifies the version of metadata. * Pointer to next fragment (if any). It’s a standard db_key.
- NULL flags for columns. They are stored as a bitmap for individual columns. NULL data is filled by zero’s to allow compression (see below).
- Record version data. If possible, data is compressed by RLE (run-length) compression that reduces repeating groups of bytes.
The use of row descriptors allows for the stable addressing of rows. The row address, the famous db_key, is a reference to a row descriptor that consists of two numbers: index of data page for a table + index of a row descriptor in the descriptor array on the data page.
Whenever a data block for a new row version is created, it replaces the previously data block, which is moved to another place, preferably on the same page. If there is no room left on the page to place the previous version there, is stored on another Data Page.
A record version is created also for deleted rows, but in this case the data block contains only the header (see data block header flags).
If there is no room on Data Page to store the newly created data block on it, the data block is split into fragments, and only first fragment is stored on this Data Page.
Bitmap with Transaction States
The bitmap with transaction states is very important, because without it it’s impossible to decide whether the particular record version must be kept in database, or whether it’s outdated and could be deleted, and whether is “visible” to a particular transaction or should be ignored etc.
Each transaction state is encoded in two bits, where:
- 00 – Active transaction
- 01 – Limbo transaction (related to two-phase commit)
- 10 – Dead (rolled back) transaction
- 11 – Committed transaction
This bitmap is also stored in database in special database pages called Transaction Inventory Pages (TIP) whenever it’s changed. The number of TIP pages needed to store the whole bitmap is defined by following formula:
(Next Transaction – OIT) / (4 transactions per byte * (1024 bytes – 16 byte header – 4 byte next TIP page number))
For example, a 1K page size can hold up to 4016 transactions.
On the first database attachment, Firebird reads the transaction state bitmap from TIP’s. If there are any transactions marked as active (which may happen after unexpected server termination), they are marked as dead (rolled back). That’s enough to rollback all uncommitted changes that are left in a database after a crash, and this is the reason why crash recovery in Firebird is so fast.
Whenever a new transaction starts, Firebird gets a new transaction number from the Database Header Page, checks and recalculate the values for OIT and OAT, adjust’s the state bitmap and writes the changes back to database (Header Page and TIP’s).
Transactions in Snapshot and Snapshot Table Stability isolation use their own copy of this bitmap, created when the transaction starts. By using this private copy, these transactions can maintain the stable view on the database that’s not influenced by transactions committed after they started. Transactions in Read Committed isolation use a shared bitmap that contains actual transaction states, so they can see changes committed after they have started.
Important transaction numbers
There are three, (previously mentioned) transaction numbers, that are important for Firebird. The number of the Oldest Interesting Transaction (OIT) and the number of the Next Transaction are important to maintain the sliding window of the Transaction State Bitmap. The OIT number can safely define the lower bound of the bitmap, because all transactions below this number were committed (or there are no record versions left from them in the database, see sweep). For healthy Firebird operations it’s necessary to keep this sliding window moving, otherwise the bitmap will utilise space in both memory and in the database.
Because the Next Transaction number is always moving up with each new transaction, it’s necessary to keep the OIT following it. The OIT transaction could be active (in this case equals to Oldest Active Transaction - OAT), stuck in limbo or a rolled back transaction.
- You can’t do much about active transactions, except to keep transactions as short as possible. If you need a long running transaction that doesn’t write any data (for example a data change monitoring daemon), you should use a Read Only transaction in Read Committed isolation that could be handled by server as pre-committed, so it doesn’t qualify itself to freeze the OIT.
- Limbo transactions can appear only on unfinished multi-database transactions that were not successfully ended (two-phase commit failed in the middle), and they need special attention from the database administrator (see gfix options to resolve limbo transactions).
- Normally, rolled back transactions are not marked as dead in the state bitmap, because Firebird keeps an undo log for each transaction. When a transaction is rolled back, the undo log is used to immediately remove all changes performed by the transaction, and the transaction is marked as committed (it’s perfectly safe, as there are no record versions in the database that originate from this transaction). But the transaction undo log is used only when a client requests an explicit rollback. It’s not used when the transaction is rolled back due to abnormal termination of client connection. Undo log can be also dropped by Firebird if it’s getting too large, or on client request (no_auto_undo transaction option).
As a safety valve for a frozen OIT that would over time would cause problems with the state bitmap, Firebird checks the difference between OIT and OAT whenever new transaction starts. If this difference exceeds defined limit known as the sweep interval database option (default 20000, see –housekeeping gfix option), Firebird starts up the sweep process. Because it’s started by the difference between OIT and OAT, this process is never started (because it wouldn’t help) when the OIT is the active transaction (the same as the OAT).
The sweep reads all record versions in the whole database, and removes all versions originating from dead transactions, so all these dead transactions can be marked as committed in the state bitmap, and OIT can then be recalculated.
How it fits together
Whenever a transaction reads a row, it starts with the first record version pointed to by the row slot, reads it and checks the stored transaction number in the state bitmap (private for Snapshot transactions, shared with recent states for Read Committed ones) if the transaction was committed (i.e. visible). If this record is not visible, the transaction continues the evaluation via the next record version in the chain and so on, until the first visible version is found, or it reaches the end of the chain.
When a transaction is going to create a new record version, it also checks the numbers and states of previous record versions, but it uses different rules to decide if the new version can be created.
The whole evaluation process can be best explained using examples.
Let’s have a transaction state bitmap as in the next table. The first column represents the bitmap of transaction states used by the transaction, the next column contains isolation levels for these transactions (a particular transaction cares only about it’s own isolation, but we’ll use this table in several examples), the third column marks OAT and OIT values.
Example 1: Transaction no. 53 (Read Committed) is reading

Let’s have a record version chain with versions from transactions 60, 56, 52, 50 and 32 (first one is the most recent one).
Firebird reads the first record version, and finds that its from transaction 60, that is still active. If the transaction is in NO RECORD VERSION mode, Firebird waits for the end of transaction 60 (requests a lock on it and then tries again. If the transaction is in RECORD VERSION mode, this version is not visible, and Firebird continues onto the next record version. This one is from transaction 56, which is committed, so this record version is returned.
Example 2: Transaction no. 53 (Read Committed) is reading (different chain)
Let’s have a record version chain with versions from transactions 60, 50 and 32 (first one is the most recent one).
Firebird reads the first record version, and finds that it’s from transaction 60, that is still active, so this version is not visible, and continues onto the next record version. This one is from transaction 50, which was rolled back, so this version is not visible too, and continues onto the next record version. The next one is from transaction 32, which is not in the table, is lower than the OIT, and hence is from a committed transaction, so this record version is returned.
Example 3: Transaction no. 53 (Read Committed) is reading (yet another chain)
Let’s have a record version chain with only one version from transaction 50.
Firebird reads the first record version, and finds that it’s from transaction 50, which was rolled back, so this version is not visible, and so wants to continue onto the next record version. But there is no other record version (it was inserted and then deleted), so no record version is returned.
Example 4: Transaction no. 55 (Snapshot) is reading
Let’s have the record version chain with versions from transactions 60, 56, 52, 50 and 32 (first one is the most recent one).
In this case, we can’t use the state bitmap as it is defined above, because transaction 55 is a Snapshot transaction, that has its own copy of a state bitmap that was created when it started. This copy obviously can’t contain states for transactions 56 and above, because they were not started at that time. Also states of transactions 54 and below could be different, but we can consider that they are the same as in our sample table.
So Firebird reads the first record version, and finds that it’s from transaction 60, and that it is higher than this one, and therefore is not visible, and so continues onto the next record version. This one is from transaction 56, which is also bigger, so Firebird continues onto the next record version. This one is from transaction 52, which is committed, so this record version is returned.
Example 5: Transaction no. 53 (Read Committed) is going to create a new record version
Let’s have the record version chain with versions from transactions 60, 58 and 52 (first one is the most recent one).
Firebird reads the first record version, and finds that it’s from transaction 60, that is still active, so its not possible to create the new record version. If the transaction is in WAIT conflict resolution mode, Firebird waits on the end of transaction 60. If transaction 60 is committed, Firebird will report an update conflict error, but if it is rolled back, the new record version is created. If the transaction is in NOWAIT conflict resolution mode, an update conflict error is reported immediately.
Example 6: Transaction no. 53 (Read Committed) is going to create a new record version (different chain)
Let’s have the record version chain with versions from transactions 56 and 52 (first one is the most recent one).
Firebird reads the first record version, and finds that it’s from transaction 56, which is newer than current one, and was committed. But current transaction is Read Committed, so the new record version is created and is then put in front of the version chain.
Example 7: Transaction no. 53 (Read Committed) is going to create a new record version (yet another chain)
Let’s have the record version chain with versions from transactions 58 and 52 (first one is the most recent one).
Firebird reads the first record version, and finds that it’s from transaction 58, that was rolled back, so this version can be ignored, and continues onto the next version. This one is from transaction 52, which is older than current transaction, and was committed, so a new record version is created and put in front of the version chain.
Chain traversal and Garbage collection
Firebird always traverses the whole record version chain, and doesn’t stop on the first visible (committed) version as you may think from previous examples. Firebird is looking for record versions that originate from dead transactions that should be permanently removed from the database. Firebird also looks for committed versions beyond OAT, and if there is more than one of them, the older ones will also be removed.
Removal of obsolete record versions is very important for Firebird’s data retrieval performance. If version chain becomes too long to fit on single page, the performance will suffer, because more pages must be read.
In the Classic architecture of the engine, the obsolete record versions are removed immediately as they are discovered. In the Super Server architecture, numbers of pages that have such obsolete versions are added to the to-do list for the garbage collection thread. This thread then picks pages from the list and removes these obsolete versions.
The Classic’s co-operative garbage collection has unpredictable effects on the performance of individual transactions, but it’s very effective in keeping the chain as short as possible. Centralised garbage collection in Super Server take the load off from individual transactions, but may result in even worse performance degradation, if the garbage collection thread is “starved”. This can happen on very busy systems with a lot of concurrent users, because the garbage collection thread runs at the same priority as other worker threads, and therefore competes with them for CPU cycles. If the worker thread generate more work than the garbage collection thread can manage, everything starts to deteriorate as worker threads spend too many CPU cycles trying to handle long version chains, and the garbage collection thread gets less and less time available to remove the long chains.
This ongoing garbage collection doesn’t ensure that all record versions from dead transactions are removed. Firebird cannot fix an OIT frozen by a dead transaction “along the way”. Only a sweep can ensure the complete removal of these versions, and fix the OIT.
Some Tips and Tricks to get the best from Firebird transactions
- Avoid use of Commit/Rollback Retaining and stable db_keys.
- Avoid designs that require many changes to a single row.
- Avoid designs that require updates as part of an insert.
- If transaction reads many rows for later update, use table reservation.
- For long-running “change monitoring“ transactions, use Read Committed with the Read Only attribute, or events.
- Do not perform many changes in nested procedures.
- Keep the number of changes per transaction reasonably small.